关于依赖关系解析的更多信息¶
本文更详细地介绍了 pip 的依赖关系解析算法。在某些情况下,pip 可能需要很长时间才能确定要安装的内容,本文旨在帮助读者了解在此过程中“幕后”发生了什么。
注意
本文档仍在编写中。所包含的详细信息是准确的(在编写时),但还有其他信息,特别是围绕 pip 与 resolvelib 的接口,尚未包含在内。
欢迎贡献以改进本文档。
依赖关系解析问题¶
在给定一组依赖关系的情况下,找到一组要安装的软件包的过程被称为 NP-hard 问题。在实践中,这意味着该过程的扩展性在问题规模增加时非常差。因此,当您有很多依赖项时,在最坏情况下,确定要安装的内容将需要很长时间。
这在实践中的含义是,总有一些情况,pip 无法在合理的时间内确定要安装的内容。我们会尽一切努力确保这种情况很少发生,但完全消除这种情况在理论上也是不可能的。我们稍后将讨论,如果您遇到这种情况,您有哪些选择。
Python 特定问题¶
许多处理依赖关系解析的算法假设您在开始时就了解问题的全部细节,即您预先了解所有依赖项。不幸的是,Python 包的情况并非如此。在当前的包索引结构中,依赖项元数据只能通过下载包文件并从中提取数据来获得。对于源代码分发,情况更糟,因为项目必须在下载后构建才能确定依赖项。
目前正在努力尝试以更低成本使元数据更易获得,但在编写本文档时,这项工作尚未完成。
由于下载项目是一个代价高昂的操作,因此 pip 无法预先计算完整的依赖树。这意味着我们无法使用多种技术来解决依赖关系解析问题。实际上,我们必须使用回溯算法。
依赖项元数据¶
值得讨论的是,为了推动包解析过程,究竟需要哪些元数据。基本上有三个关键信息
项目名称
发行版本
依赖项本身
还有其他一些数据(例如,额外的信息、Python 版本限制、轮子兼容性标签),这些数据也会被使用,但它们不会从根本上改变这个过程,所以在这里我们忽略它们。
最重要的信息是项目名称和版本。这两个信息标识了要安装的单个“候选者”,并且必须唯一地标识此类候选者。名称和版本必须从创建候选者对象时就可用。对于分发文件(sdists 和轮子),这不是问题,因为该数据可以从文件名中获取,但对于未打包的源代码树,pip 需要调用构建后端以请求该数据。这是在解析本身开始之前完成的。
依赖项数据不会事先请求(如上所述,这样做会非常昂贵,对于回溯算法来说,它并不是必需的)。相反,pip 在算法开始检查该特定候选者时“按需”请求依赖项数据。
延迟获取依赖项数据的一个特殊含义是,pip 通常不知道那些对查看整个依赖树的人来说很明显的事情。例如,如果软件包 A 依赖于软件包 B 的 1.0 版本,那么对于人类来说,很明显,没有必要查看软件包 B 的其他版本。但是,如果 pip 在考虑 A 之前就开始查看 B,那么它没有访问 A 的依赖项数据,因此无法知道查看 B 的其他版本是浪费时间。更糟糕的是,pip 甚至无法知道 A 的依赖项中存在关键信息。
后一点是 pip 完成解析需要很长时间的许多情况中的一个常见主题,即 pip 在做出“错误”选择时不知道的信息。添加到解析器中的大多数启发式方法旨在在此类缺乏知识的情况下做出正确的猜测。
解析器和查找器¶
到目前为止,我们一直将“解析器”视为一个单一的实体。虽然这在很大程度上是正确的,但从索引获取包数据的过程由 pip 的另一个组件“查找器”处理。查找器负责向解析器提供候选者,并在选择合适的候选者方面发挥着关键作用。
请注意,解析器仅与从索引获取的包相关。来自其他来源(本地源代码目录、直接 URL 引用)的候选者不会通过查找器,而是与查找器提供的候选者合并,作为解析器“提供者”实现的一部分。
除了确定索引中给定项目存在哪些版本之外,查找器还会选择要用于该候选者的最佳分发文件。这可能是一个轮子或一个源代码分发,确切选择什么由轮子兼容性标签、pip 的选项(是否优先选择二进制文件或源代码)以及索引提供的元数据控制。特别是,如果文件被标记为仅供特定 Python 版本使用,则该文件将被查找器忽略(解析器可能甚至不会看到该版本)。
查找器还会根据优先级将项目的候选者提供给解析器,例如,提供者会实现规则,即较新版本优先于较旧版本。
解析器算法¶
解析器本身基于一个单独的包,resolvelib。它实现了一种抽象的回溯解析算法,这种算法与 Python 包的具体细节无关,这些细节在调用解析器之前被 pip 抽象出来。
Pip 与 resolvelib 的接口采用“提供者”的形式,这是 pip 的包模型与解析算法之间的接口。提供者处理“候选者”和“需求”,并实现以下操作
identify- 为候选者和需求实现标识。正是此操作实现了候选者通过其名称和版本进行标识的规则,例如。get_preference- 这会向解析器提供信息,以帮助它选择在执行解析过程时“接下来”要查看哪个需求。find_matches- 给定一组约束,确定哪些候选者满足这些约束。这基本上是查找器与解析器交互的地方。is_satisfied_by- 检查候选者是否满足需求。这基本上是需求含义的实现。get_dependencies- 获取候选者的依赖项元数据。这是获取和读取包元数据过程的实现。
在这些方法中,唯一非平凡的方法是 get_preference 方法。它实现了用于指导解析的启发式方法,告诉它接下来尝试满足哪个需求。正是此方法负责猜测通过依赖树的哪条路线将是最有效的。如上所述,它是在信息有限的情况下完成的。请参见下图
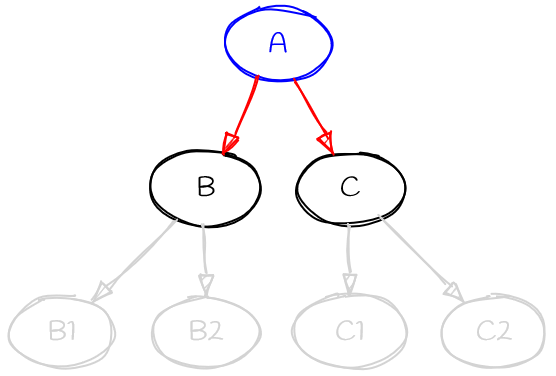
当要求提供者在红色需求 (A->B 和 A->C) 之间进行选择时,它对 B 或 C 的依赖项 (即图的灰色部分) 一无所知。
Pip 的当前提供者实现以以下方式实现 get_preference
如果任何已知需求是“直接的”,例如指向明确的 URL,则优先考虑。
如果相等,则优先考虑任何需求是“固定的”,即包含运算符
===或==。如果相等,则计算一个近似的“深度”,并首先解决更接近用户指定需求的需求。
按照用户指定的顺序排列需求。
如果顺序相同,优先考虑“非自由”需求,即包含至少一个运算符,例如
>=或<。如果顺序相同,则按字母顺序排序以保持一致性(有助于调试)。